
USC Institute for Creative Technologies is proud to announce that Kevin Hyekang Joo, PhD student in Computer Science and AI researcher at ICT under the supervision of Prof. Mohammad Soleymani, has had two papers and a Doctoral Consortium short paper accepted to the 27th ACM International Conference on Multimodal Interaction (ICMI 2025) as a first author and will present his research in Canberra, Australia, this October. Among them, “Multimodal Fusion with LLMs for Engagement Prediction in Natural Conversation” was accepted for presentation at the Workshop on Holistic and Responsible Affective Intelligence at ICMI ‘25 and received the Best Paper Award! Furthermore, his paper, “Multimodal Behavioral Characterization of Dyadic Alliance in Support Groups,” won the Oral Presentation at ICMI ‘25. In this essay, Kevin Joo talks about his research on social AI, including modeling of social dynamics and affective states from multimodal data, with applications spanning education, mental health, and human-robot interaction.
BYLINE: Kevin Hyekang Joo, PhD student, Computer Science, Viterbi School of Engineering, USC; AI Researcher, {Intelligent Human Perception Lab, Affective Computing Group}, USC Institute of Creative Technologies
As artificial intelligence becomes more embedded in our everyday lives, the ability for machines to understand how we communicate – not just what we say – is becoming critical. At the University of Southern California Institute for Creative Technologies (USC ICT), under the guidance of Prof. Mohammad Soleymani in the Intelligent Human Perception Lab, I have been pursuing research into how AI systems can better understand the dynamics of human social interaction.
I’m honored that two of my research papers [1, 2] and an extended abstract [3] have been accepted to the 27th ACM International Conference on Multimodal Interaction (ICMI 2025), where I’ll be presenting in Canberra, Australia, this October. Each of these studies represents a step toward a broader goal: creating socially aware AI systems that can detect, model, and respond to subtle cues in human behavior, and comprehend the dynamics of human social interaction, improving their ability to collaborate, care, teach, and support us.
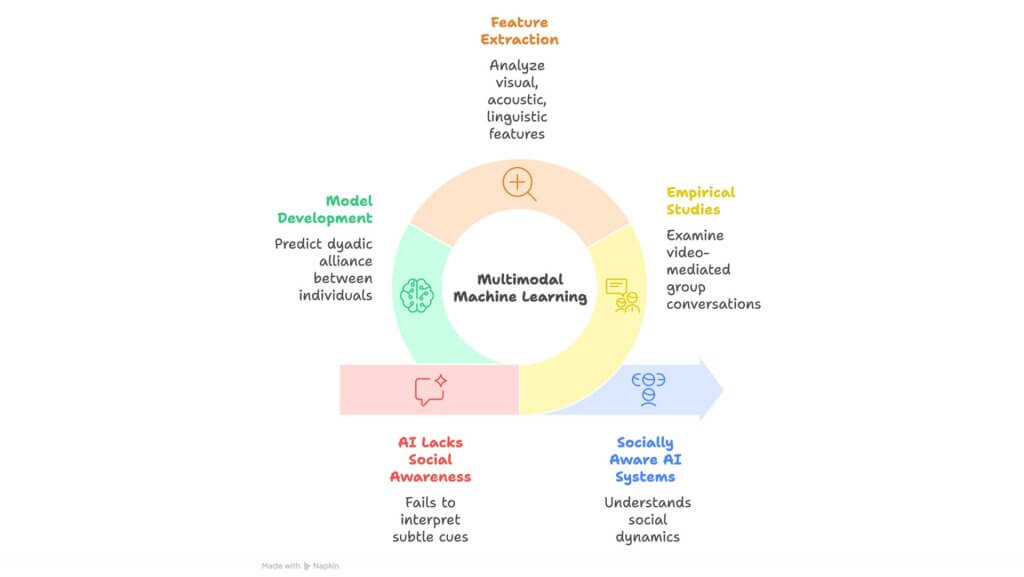
Multimodal Behavioral Characterization of Dyadic Alliance in Support Groups [1]
Our social lives are built on moment-to-moment cues – head nods, gaze shifts, vocal inflections, smiles, or silence. These subtle signals shape our perceptions of each other, particularly in conversational contexts. But despite impressive progress in natural language processing and computer vision, machines still struggle to interpret such behaviors holistically.
One major strand of my research addresses this gap. We conducted empirical studies examining video-mediated conversations in small group settings to explore how verbal and nonverbal behaviors influence dyadic alliance – the quality of the peer-to-peer social bond.
We studied 18 group sessions involving a total of 96 participants, each session guided by a robot-embodied virtual facilitator. The participants discussed common challenges such as anxiety and stress, while their verbal and nonverbal behavior was recorded and analyzed post-hoc. After the session, each participant rated their sense of connection with every other group member through several questions in the post-session questionnaire.
Using a multimodal machine learning framework, we developed models to predict dyadic alliance between any two individuals within the same group, based on visual, acoustic, and linguistic features, such as facial expressions, head gestures, speech, and prosody.
What we found was striking: listener head nods and brow raises, along with speaker pitch variation and head movements, strongly predicted perceived alliance. Meanwhile, surprisingly, both the speaker’s and listener’s frowns showed a negative correlation with alliance. These results show that not all cues are equally informative – and that context and interactional roles matter. Through role-specific modeling and modality ablation, we identified which behaviors were most predictive in each role. This sets the stage for more context-sensitive AI systems that can learn not just what behavior looks like, but why it matters.
This work, to our knowledge, represents the first computational model for estimating dyadic alliance, as perceived by members of support groups. Beyond its technical contributions, it offers important insights for health technology: systems that can monitor group dynamics in real time could support facilitators, improve therapeutic outcomes, and expand access to care.
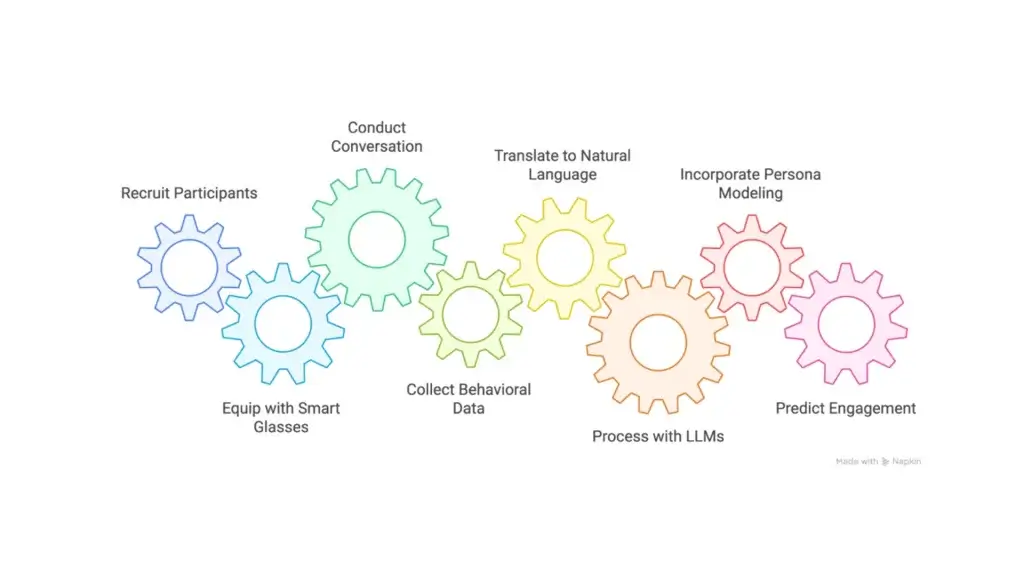
Engagement Prediction Using Smart Glasses and LLMs [2]
The second study examines how wearable devices and large language models (LLMs) can measure social engagement in the real-world natural settings. We recruited 34 participants for this study, in which two participants sat face-to-face for a 15-minute conversation. We outfitted each participant with smart glasses, equipped with gaze-tracking cameras, microphones, and multiple sensors, including an IMU, and captured their conversations for about 15 minutes. Participants later rated their perceived engagement levels during the natural conversation with their dyadic partner through a series of questions on a Likert scale, providing the ground truth for our model.
Our primary innovation is a new method for processing this behavioral data. To process behavioral data, multimodal cues for each person were translated into natural language – a type of “multimodal transcript” – as opposed to traditional fusion methods, which combine signals at the feature or decision level. Through empirical experiments, this approach proved not only competitive with traditional techniques but also offered new advantages in transparency, interpretability, and privacy.
Our use of persona-driven modeling also introduces a novel dimension: by incorporating inferred beliefs, traits, and behavioral patterns, we enable the LLM to reason about a participant’s engagement based on a richer internal context. This work marks a significant step toward integrating complex social reasoning into AI models.
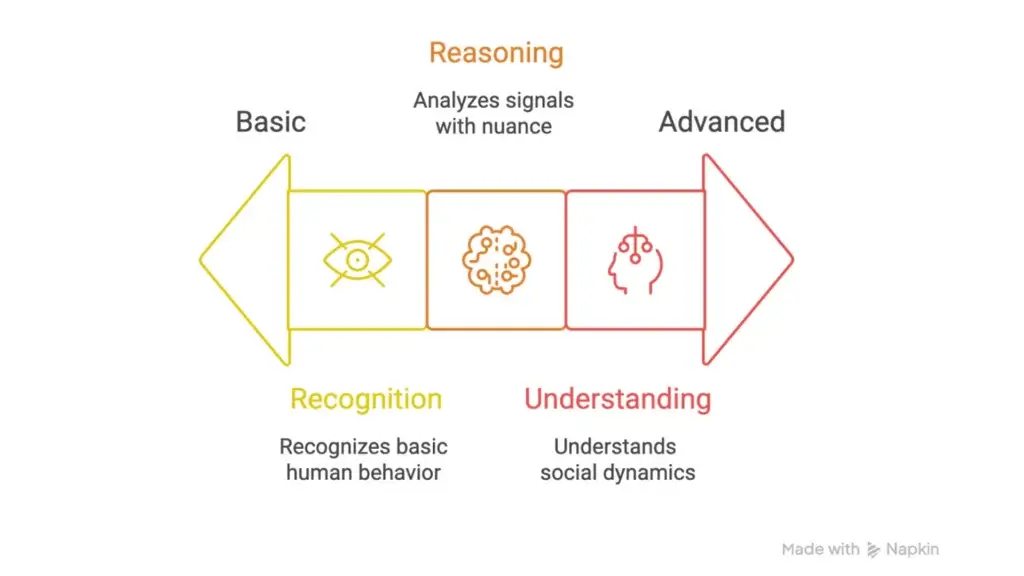
Toward Socially Intelligent AI
These papers reflect a broader mission: to move beyond surface-level recognition of human behavior, and toward computational models that truly understand social dynamics.
AI systems that can interpret our signals with nuance – knowing when we’re engaged, when we feel connected, when we’re struggling – can have profound real-world applications. In education, robots or virtual tutors could respond dynamically to student engagement. In therapy or coaching, AI could help track client rapport or emotional shifts. In healthcare, socially attuned machines could assist with elder care, rehabilitation, or group therapy.
But this vision also raises challenges. Social cues are ambiguous and vary widely across individuals and cultures. Data can be noisy, and human reactions are deeply contextual. That’s why much of our work focuses on building interpretable, robust, and privacy-aware models. We aim not just to improve accuracy, but to understand why a model makes its predictions, and to ensure those predictions are grounded in behavioral science. Furthermore, we analyze both nonverbal and verbal cues – visual, linguistic, and acoustic – together to better understand the complexity of human communicative behaviors.
Looking ahead, I’m excited to explore how these findings can be scaled to larger group contexts, integrated with full-body gesture and posture analysis, and embedded into interactive systems. We hope to create AI that doesn’t just perform, but perceives—AI that can truly read the room.
//
[1] Kevin Hyekang Joo, Zongjian Li, Yunwen Wang, Yuanfeixue Nan, Mina Kian, Shriya Upadhyay, Maja Mataric, Lynn Miller, and Mohammad Soleymani. “Multimodal Behavioral Characterization of Dyadic Alliance in Support Groups.” In Proceedings of the 27th International Conference on Multimodal Interaction (ICMI 2025). Association for Computing Machinery, 2025. Oral Presentation.
[2] Cheng Charles Ma*, Kevin Hyekang Joo*, Alexandria K. Vail*, Sunreeta Bhattacharya, Álvaro Fernández García, Kailana Baker-Matsuoka, Sheryl Mathew, Lori L. Holt, and Fernando De la Torre. “Multimodal Fusion with LLMs for Engagement Prediction in Natural Conversation.” In Companion Proceedings of the 27th International Conference on Multimodal Interaction (ICMI 2025). Association for Computing Machinery, 2025. Best Workshop Paper Award.
[3] Kevin Hyekang Joo. “Modeling Social Dynamics from Multimodal Cues in Natural Conversations.” In Proceedings of the 27th International Conference on Multimodal Interaction (ICMI 2025). Association for Computing Machinery, 2025.
//